Prediction
ACLYSIS supports to segregate the loan applicants by analysing their demographic details and credit history in terms of probability of defaults. It also enables the user to implement scoring norms for Risk Ratings.
Background
It is obvious for any financial institution to perform credit risk analysis to determine the borrower’s creditworthiness to meet debt obligations and to reduce the risk exposure towards losses. It also helps to decide upon the applicable rate of interest to compensate the high risk of default.
Data in hand
The data consists of default details of a set of customers a Bank. Among those, ‘’Loan_Status’’ is our target / dependent variable and we can use machine learning to predict possibility of being a defaulter for a new set of individuals.
For demo purposes, this dataset has already been uploaded to Aclysis. But by just selecting "Connect Data Source," you can upload whatever dataset you desire.
We'll look at how to create and use a predicting model below. You must first log in with us. The home page will appear as.

Once you click "Add New Model" on the home page, the interface shown below will appear.

Then, upload the dataset by clicking "Import Table." When it is uploaded, you will receive a scrollable preview of the dataset along with an overview that includes the number of rows, columns, the dataset name, the most recent upload date, and the distribution of each variable. To move on to the following step, click "Save & Continue."

Building the Model
We can now select the second step, "Manipulate Data," to rename columns, remove unnecessary features and duplicate rows, treat outliers, etc. The display will be
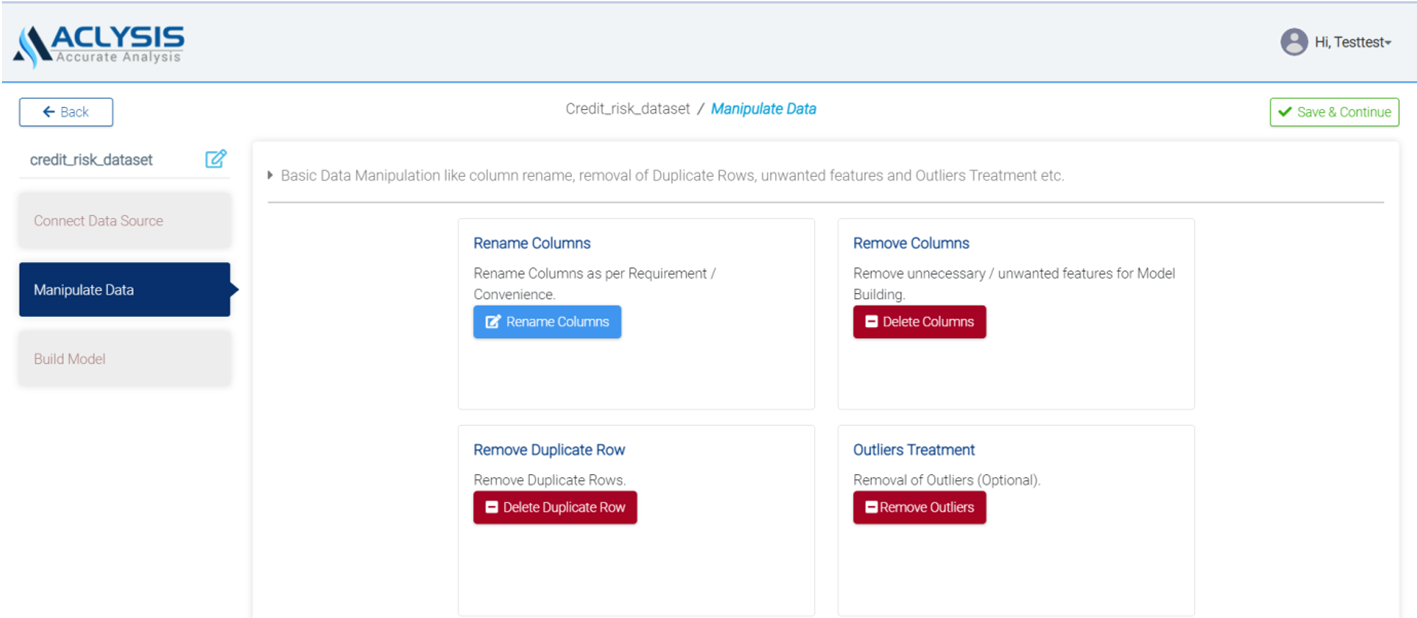
To continue to step 3, "Build Model" where a model is built and results are obtained, click "Save & Continue". You will have a variety of model choices to consider. For building model under AutoML option, you must pick the features you wish to use to build the model and the target variable in this phase. As soon as you submit the details, the model will automatically build, and you will see the following display with model accuracy and various visuals, such as the target variable distribution (both percent & count wise), feature importance, segmentations, classification report, accurate vs. prediction plot and conclusion for your ready reference.

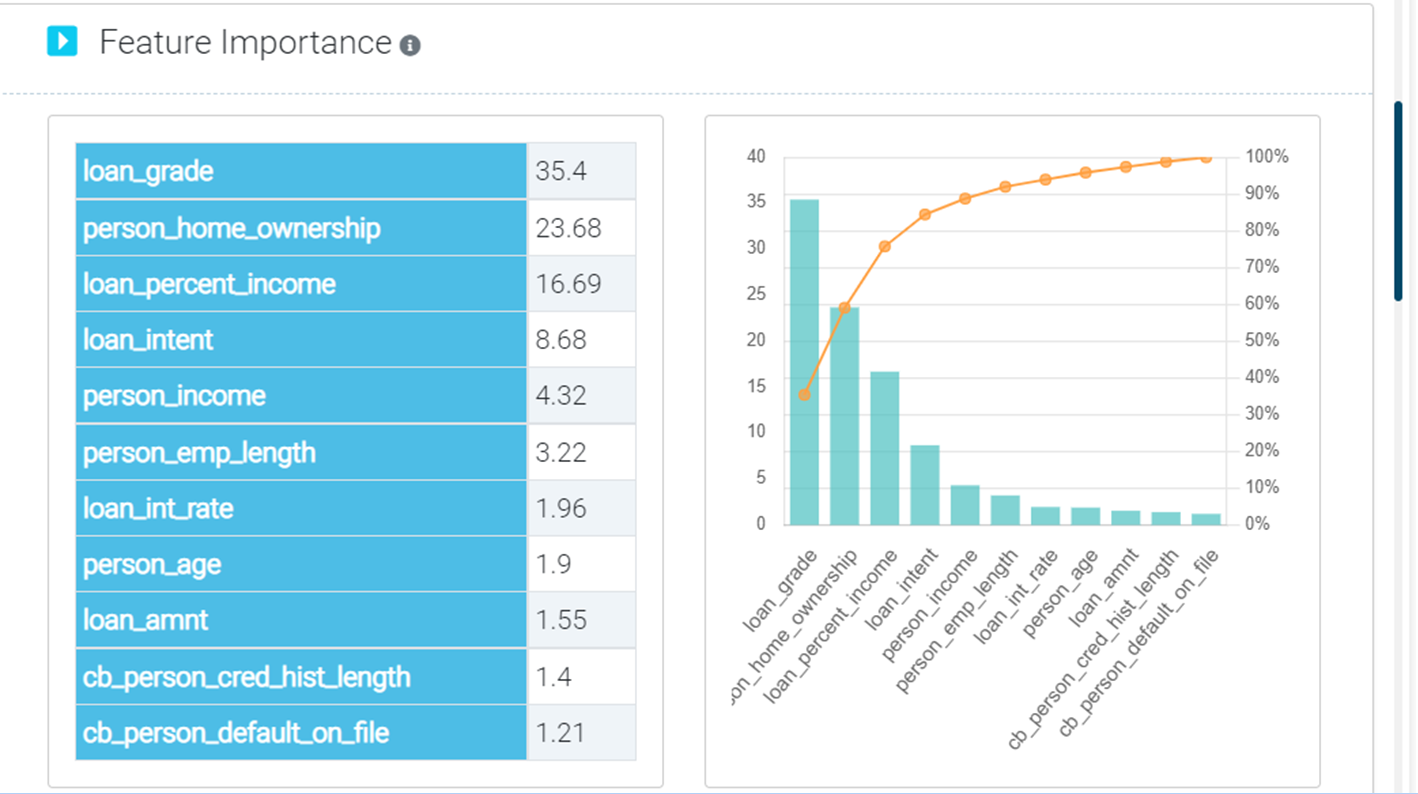
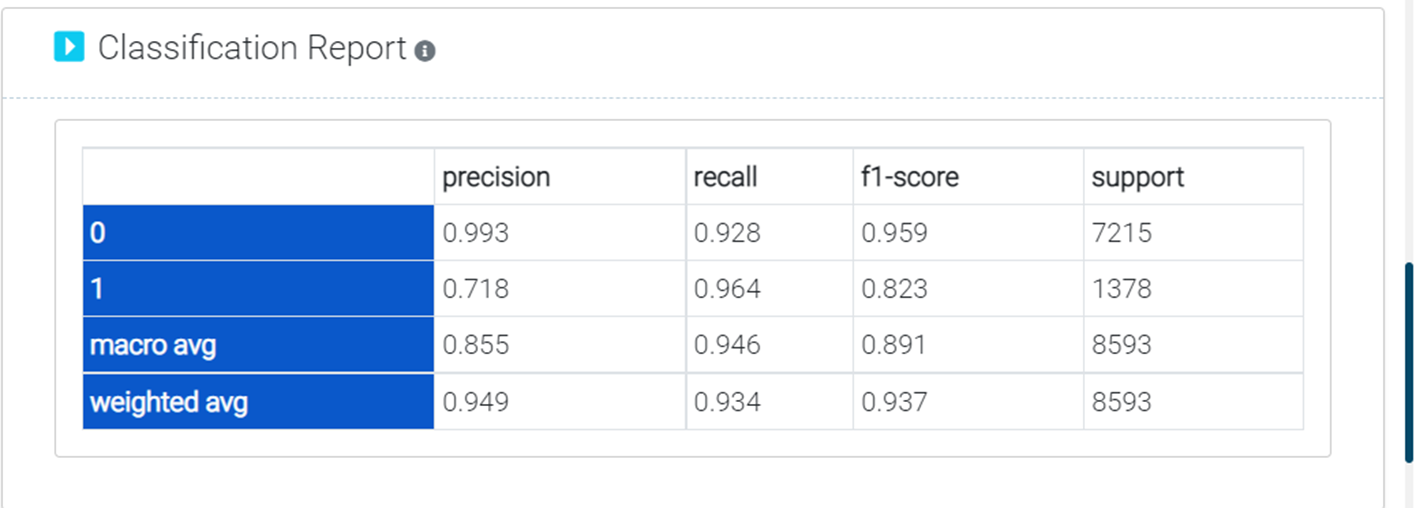



Additionally, bear in mind that you are not needed to pay for model training time, unlike many popularly used automated machine learning programmes, so feel free to develop as many models as you like. As a result, we have discovered that it is comparatively easy to build a very accurate prediction model.
Deploying the Model
It's time to use the model we've created in the actual world.
Using Aclysis, deploying sophisticated machine learning models is simple. To deploy using a web app, you click "Deploy Model." For example, if you select "Web App," you will be asked to provide feature inputs. As soon as values are provided, the prediction for the target variable is quickly shown. You can upload a file and get the matching forecasts in tabular form instead of entering a single set of numbers. Here is an example of a deployment page with a csv file:

Any categorical feature of your interest can be predicted using the same procedures we used. You can connect historical data to Aclysis, choose a column to forecast, and deploy using a variety of techniques as long as you have the data.